POS-Tagging and Syntactic Parsing with R
Martin Schweinberger
2021-10-01

Introduction
This tutorial introduces part-of-speech tagging and syntactic parsing using R. The entire R markdown document for this tutorial can be downloaded here. Another highly recommendable tutorial on part-of-speech tagging in R produced by Andreas Niekler and Gregor Wiedemann can be found here (see Wiedemann and Niekler 2017).
1 Part-Of-Speech Tagging
Many analyses of language data require that we distinguish different parts of speech. In order to determine the word class of a certain word, we use a procedure which is called part-of-speech tagging (commonly referred to as pos-, pos-, or PoS-tagging). pos-tagging is a common procedure when working with natural language data. Despite being used quite frequently, it is a rather complex issue that requires the application of statistical methods that are quite advanced. In the following, we will explore different options for pos-tagging and syntactic parsing.
Parts-of-speech, or word categories, refer to the grammatical nature or category of a lexical item, e.g. in the sentence Jane likes the girl each lexical item can be classified according to whether it belongs to the group of determiners, verbs, nouns, etc. pos-tagging refers to a (computation) process in which information is added to existing text. This process is also called annotation. Annotation can be very different depending on the task at hand. The most common type of annotation when it comes to language data is part-of-speech tagging where the word class is determined for each word in a text and the word class is then added to the word as a tag. However, there are many different ways to tag or annotate texts.
Pos–tagging assigns part-of-speech tags to character strings (these represent mostly words, of course, but also encompass punctuation marks and other elements). This means that pos–tagging is one specific type of annotation, i.e. adding information to data (either by directly adding information to the data itself or by storing information in e.g. a list which is linked to the data). It is important to note that annotation encompasses various types of information such as pauses, overlap, etc. pos–tagging is just one of these many ways in which corpus data can be enriched. Sentiment Analysis, for instance, also annotates texts or words with respect to its or their emotional value or polarity.
Annotation is required in many machine-learning contexts because annotated texts are commonly used as training sets on which machine learning or deep learning models are trained that then predict, for unknown words or texts, what values they would most likely be assigned if the annotation were done manually. Also, it should be mentioned that by many online services offer pos-tagging (e.g. here or here.
When pos–tagged, the example sentence could look like the example below.
- Jane/NNP likes/VBZ the/DT girl/NN
In the example above, NNP stands for proper noun (singular), VBZ stands for 3rd person singular present tense verb, DT for determiner, and NN for noun(singular or mass). The pos-tags used by the openNLPpackage are the Penn English Treebank pos-tags. A more elaborate description of the tags can be found here which is summarised below:
Assigning these pos-tags to words appears to be rather straight forward. However, pos-tagging is quite complex and there are various ways by which a computer can be trained to assign pos-tags. For example, one could use orthographic or morphological information to devise rules such as. . .
If a word ends in ment, assign the pos-tag
NN(for common noun)If a word does not occur at the beginning of a sentence but is capitalized, assign the pos-tag
NNP(for proper noun)
Using such rules has the disadvantage that pos-tags can only be assigned to a relatively small number of words as most words will be ambiguous – think of the similarity of the English plural and the English past tense morpheme,for instance, which are orthographically identical.Another option would be to use a dictionary in which each word is as-signed a certain pos-tag and a program could assign the pos-tag if the word occurs in a given text. This procedure has the disadvantage that most words belong to more than one word class and pos-tagging would thus have to rely on additional information.The problem of words that belong to more than one word class can partly be remedied by including contextual information such as. .
- If the previous word is a determiner and the following word is a common noun, assign the pos-tag
JJ(for a common adjective)
This procedure works quite well but there are still better options.The best way to pos-tag a text is to create a manually annotated training set which resembles the language variety at hand. Based on the frequency of the association between a given word and the pos-tags it is assigned in the training data, it is possible to tag a word with the pos-tag that is most often assigned to the given word in the training data.All of the above methods can and should be optimized by combining them and additionally including pos–n–grams, i.e. determining a pos-tag of an unknown word based on which sequence of pos-tags is most similar to the sequence at hand and also most common in the training data.This introduction is extremely superficial and only intends to scratch some of the basic procedures that pos-tagging relies on. The interested reader is referred to introductions on machine learning and pos-tagging such as e.g.https://class.coursera.org/nlp/lecture/149.
There are several different R packages that assist with pos-tagging texts (see Kumar and Paul 2016). In this tutorial, we will use the openNLP, the corNLP, and the TreeTagger packages. Each of these has advantages and shortcomings and it is advantageous to try which result best matches one’s needs.
Preparation and session set up
This tutorial is based on R. If you have not installed R or are new to it, you will find an introduction to and more information how to use R here. For this tutorials, we need to install certain packages from an R library so that the scripts shown below are executed without errors. Before turning to the code below, please install the packages by running the code below this paragraph. If you have already installed the packages mentioned below, then you can skip ahead ignore this section. To install the necessary packages, simply run the following code - it may take some time (between 1 and 5 minutes to install all of the libraries so you do not need to worry if it takes some time).
# install packages
install.packages("tidyverse")
install.packages("igraph")
install.packages("tm")
install.packages("NLP")
install.packages("openNLP")
install.packages("openNLPdata")
install.packages("coreNLP")
install.packages("koRpus")
install.packages("koRpus.lang.en", repos="https://undocumeantit.github.io/repos/l10n/")
install.packages("koRpus.lang.de", repos="https://undocumeantit.github.io/repos/l10n/")
install.packages("koRpus.lang.es", repos="https://undocumeantit.github.io/repos/l10n/")
install.packages("koRpus.lang.nl", repos="https://undocumeantit.github.io/repos/l10n/")
install.packages("koRpus.lang.it", repos="https://undocumeantit.github.io/repos/l10n/")
install.packages("koRpus.lang.fr", repos="https://undocumeantit.github.io/repos/l10n/")
install.packages("koRpus.lang.pt", repos="https://undocumeantit.github.io/repos/l10n/")
install.packages("koRpus.lang.ru", repos="https://undocumeantit.github.io/repos/l10n/")
install.packages("flextable")
# install phrasemachine
phrasemachineurl <- "https://cran.r-project.org/src/contrib/Archive/phrasemachine/phrasemachine_1.1.2.tar.gz"
install.packages(phrasemachineurl, repos=NULL, type="source")
# install parsent
pacman::p_load_gh(c("trinker/textshape", "trinker/parsent"))
# install klippy for copy-to-clipboard button in code chunks
remotes::install_github("rlesur/klippy")
NOTE
Downloading and installing the jar files for CoreNLP will take quite long (between 5 and 10 minutes!). The installation will also require data from your plan (the files are app. 350 MB) - it is thus recommendable to be logged into an institutional network that has a decent connectivity and download rate (e.g., a university network).
# download java files for CoreNLP
downloadCoreNLP()Now that we have installed the packages, we activate them as shown below.
# set options
options(stringsAsFactors = F) # no automatic data transformation
options("scipen" = 100, "digits" = 4) # suppress math annotation
# load packages
library(tidyverse)
library(igraph)
library(tm)
library(NLP)
library(openNLP)
library(openNLPdata)
library(coreNLP)
library(koRpus)
library(koRpus.lang.en)
library(koRpus.lang.de)
library(koRpus.lang.es)
library(koRpus.lang.nl)
library(koRpus.lang.it)
library(koRpus.lang.fr)
library(koRpus.lang.pt)
library(koRpus.lang.ru)
library(phrasemachine)
library(flextable)
# load function for pos-tagging objects in R
source("https://slcladal.github.io/rscripts/POStagObject.r")
# syntax tree drawing function
source("https://slcladal.github.io/rscripts/parsetgraph.R")
# activate klippy for copy-to-clipboard button
klippy::klippy()Once you have installed R and RStudio and initiated the session by executing the code shown above, you are good to go.
2 POS-Tagging with openNLP
In R we can pos–tag large amounts of text by various means. This section explores pos-tagging using the openNLP package. Using the openNLP package for pos-tagging works particularly well when the aim is to pos-tag newspaper texts as the openNLP package implements the Apache OpenNLPMaxent Part of Speech tagger and it comes with pre-trained models. Ideally, pos-taggers should be trained on data resembling the data to be pos-tagged.However, I do not know how to trained the Apache openNLP pos-tagger via R and it would be great if someone would provide a tutorial on how to do that. Using pre-trained models has the advantage that we do not need to train the pos-tagger ourselves. However, it also means that one has to rely on models trained on data that may not really resemble the data a at hand.This implies that using it for texts that differ from newspaper texts, i.e.the language the models have been trained on, does not work as well, as the model applies the probabilities of newspaper language to the language variety at hand. pos-tagging with the openNLP requires the NLP package and installing the models on which the openNLP package is based.
To pos-tag a text, we start by loading an example text into R.
# load corpus data
text <- readLines("https://slcladal.github.io/data/testcorpus/linguistics07.txt", skipNul = T)
# clean data
text <- text %>%
str_squish() . |
Related areas of study also includes the disciplines of semiotics (the study of direct and indirect language through signs and symbols), literary criticism (the historical and ideological analysis of literature, cinema, art, or published material), translation (the conversion and documentation of meaning in written/spoken text from one language or dialect onto another), and speech-language pathology (a corrective method to cure phonetic disabilities and dis-functions at the cognitive level). |
Now that the text data has been read into R, we can proceed with the part-of-speech tagging. To perform the pos-tagging, we load the function for pos-tagging, load the NLP and openNLP packages.
NOTE
You need to change the path that is used in the code below and include the path to en-pos-maxent.bin on your computer!
POStag <- function(object){
require("stringr")
require("NLP")
require("openNLP")
require("openNLPdata")
# define paths to corpus files
corpus.tmp <- object
# define sentence annotator
sent_token_annotator <- openNLP::Maxent_Sent_Token_Annotator()
# define word annotator
word_token_annotator <- openNLP::Maxent_Word_Token_Annotator()
# define pos annotator
pos_tag_annotator <- openNLP::Maxent_POS_Tag_Annotator(language = "en", probs = FALSE,
# WARNING: YOU NEED TO INCLUDE YOUR OWN PATH HERE!
model = "C:\\Users\\marti\\OneDrive\\Dokumente\\R\\win-library\\4.1\\openNLPdata\\models\\en-pos-maxent.bin")
# convert all file content to strings
Corpus <- lapply(corpus.tmp, function(x){
x <- as.String(x) } )
# loop over file contents
lapply(Corpus, function(x){
y1 <- NLP::annotate(x, list(sent_token_annotator, word_token_annotator))
y2<- NLP::annotate(x, pos_tag_annotator, y1)
y2w <- subset(y2, type == "word")
tags <- sapply(y2w$features, '[[', "POS")
r1 <- sprintf("%s/%s", x[y2w], tags)
r2 <- paste(r1, collapse = " ")
return(r2) } )
}We now apply this function to our text.
# pos tagging data
textpos <- POStag(object = text). |
Related/JJ areas/NNS of/IN study/NN also/RB includes/VBZ the/DT disciplines/NNS of/IN semiotics/NNS (/-LRB- the/DT study/NN of/IN direct/JJ and/CC indirect/JJ language/NN through/IN signs/NNS and/CC symbols/NNS )/-RRB- ,/, literary/JJ criticism/NN (/-LRB- the/DT historical/JJ and/CC ideological/JJ analysis/NN of/IN literature/NN ,/, cinema/NN ,/, art/NN ,/, or/CC published/JJ material/NN )/-RRB- ,/, translation/NN (/-LRB- the/DT conversion/NN and/CC documentation/NN of/IN meaning/NN in/IN written/spoken/VBN text/NN from/IN one/CD language/NN or/CC dialect/NN onto/IN another/DT )/-RRB- ,/, and/CC speech-language/NN pathology/NN (/-LRB- a/DT corrective/JJ method/NN to/TO cure/VB phonetic/JJ disabilities/NNS and/CC dis-functions/NNS at/IN the/DT cognitive/JJ level/NN )/-RRB- ./. |
The resulting vector contains the part-of-speech tagged text and shows that the function fulfills its purpose in automatically pos-tagging the text. The pos-tagged text could now be processed further, e.g. by extracting all adjectives in the text or by creating concordances of nouns ending in ment.
POS-Tagging non-English texts
By default, openNLP is only able to handle English text. However, the functionality of openNLP can be extended to languages other than English. In order to extend openNLP’s functionality, you need to download the available language models from http://opennlp.sourceforge.net/models-1.5/ and save them in the models folder of the openNLPdata package in your R library.
To ease the implementation of openNLP-based pos-tagging, we will write functions for pos-tagging that we can then apply to the texts that we want to tag rather than executing a piping of commands.
POS-Tagging a Dutch text
One of the languages that openNLP can handle is Dutch. To pos-tag Dutch texts, we write a function that we can then apply to the Dutch text in order to pos-tag it.
postag_nl <- function(object){
require("stringr")
require("NLP")
require("openNLP")
require("openNLPdata")
# define sentence annotator
sent_token_annotator <- openNLP::Maxent_Sent_Token_Annotator()
# define word annotator
word_token_annotator <- openNLP::Maxent_Word_Token_Annotator()
# define pos annotator
pos_tag_annotator <- openNLP::Maxent_POS_Tag_Annotator(language = "nl", probs = FALSE, model = "C:\\Users\\marti\\OneDrive\\Dokumente\\R\\win-library\\4.1\\openNLPmodels.nl\\models\\nl-pos-maxent.bin")
# convert all file content to strings
Corpus <- lapply(object, function(x){
x <- as.String(x) } )
# loop over file contents
lapply(Corpus, function(x){
y1 <- NLP::annotate(x, list(sent_token_annotator, word_token_annotator))
y2<- NLP::annotate(x, pos_tag_annotator, y1)
y2w <- subset(y2, type == "word")
tags <- sapply(y2w$features, '[[', "POS")
r1 <- sprintf("%s/%s", x[y2w], tags)
r2 <- paste(r1, collapse = " ")
return(r2) } )
}We now apply this function to our text.
dutchtext <- readLines("D:\\Uni\\UQ\\SLC\\LADAL\\SLCLADAL.github.io\\data/dutch.txt")
# pos tagging data
textpos_nl <- postag_nl(object = dutchtext). |
Taalkunde/N ,/Punc ook/Adv wel/Adv taalwetenschap/N of/Conj linguïstiek/N ,/Punc is/V de/Art wetenschappelijke/Adj studie/N van/Prep de/Art natuurlijke/Adj talen/N ./Punc |
POS-Tagging a German text
postag_de <- function(object){
require("stringr")
require("NLP")
require("openNLP")
require("openNLPdata")
# define sentence annotator
sent_token_annotator <- openNLP::Maxent_Sent_Token_Annotator()
# define word annotator
word_token_annotator <- openNLP::Maxent_Word_Token_Annotator()
# define pos annotator
pos_tag_annotator <- openNLP::Maxent_POS_Tag_Annotator(language = "de", probs = FALSE, model = "C:\\Users\\marti\\OneDrive\\Dokumente\\R\\win-library\\4.1\\openNLPmodels.de\\models/de-pos-maxent.bin")
# convert all file content to strings
Corpus <- lapply(object, function(x){
x <- as.String(x) } )
# loop over file contents
lapply(Corpus, function(x){
y1 <- NLP::annotate(x, list(sent_token_annotator, word_token_annotator))
y2<- NLP::annotate(x, pos_tag_annotator, y1)
y2w <- subset(y2, type == "word")
tags <- sapply(y2w$features, '[[', "POS")
r1 <- sprintf("%s/%s", x[y2w], tags)
r2 <- paste(r1, collapse = " ")
return(r2) } )
}We now apply this function to our text.
gertext <- readLines("D:\\Uni\\UQ\\SLC\\LADAL\\SLCLADAL.github.io\\data/german.txt")
# pos tagging data
textpos_de <- postag_de(object = gertext). |
Sprachwissenschaft/NN untersucht/VVFIN in/APPR verschiedenen/ADJA Herangehensweisen/NN die/ART menschliche/ADJA Sprache/NN ./$. |
NOTE
You need to change the path that is used in the code below and include the path to en-pos-maxent.bin on your computer!
3 POS-Tagging with TreeTagger
An alternative to openNLP for pos-tagging texts in R is the koRpus package. The koRpus package uses the TreeTagger which means that the TreeTagger has to be installed prior to pos-tagging based on koRpus package. The koRpus package simply accesses the TreeTagger via R. The fact that the the implementation of the TreeTagger requires software outside of R that has to be installed separately and prior to being able to use the koRpus package and its functions in R represents a major disadvantage compared to the openNLP approach (which also relies on external software but this is contained within the openNLP package). In addition, the installation of the TreeTagger can be quite tedious to implement (in case you are running a Windows machine as I do). On the other hand, the koRpus package has the advantage that the TreeTagger encompasses more languages than the openNLP package and the TreeTagger can be relatively easily modified and trained on new data.
Installation on Windows
As the installation of the TreeTagger can be somewhat tedious and time consuming, I would like to expand on what I did to get it going as this might save you some time and frustration.
The first thing you should do is to install or re-install a Perl interpreter. You can simply do so by clicking here and following the installation instructions.
Download the TreeTagger (click here for a Windows-64 version and here for a Windows-32 version). Move the zip-file to the root directory on your C-drive (C:/) and extract the zip file.
Download the parameter files for the languages you need (you will find the parameters files under Parameter files here). Then decompress the parameter files and move them to the sub-directory
TreeTagger/lib. Rename the parameter files to<language>-utf8.par. For example, rename the filefrench-par-linux-3.2-utf8.binasfrench-utf8.par.Now you need to set a path variable. You need to add the path
C:\TreeTagger\binto thePATHenvironment variable. How to do this differs across Windows versions. You can find a video tutorial on how to change path variables in Windows 10 here. If you have a different Windows version, e.g. Windows 7, I recommend you search for Set path variable in Windows 7 on YouTube and follow the instructions.Next, open a command prompt window and type the command:
set PATH=C:\TreeTagger\bin;%PATH%- Then, go to the directory C:by typing the command:
cd c:\TreeTagger- Now, everything should be running and you can test the tagger, e.g. by pos-tagging the TreeTagger installation file. To do this, type the command:
tag-english INSTALL.txtIf you do not get the pos-tagged results after a few seconds, restart your computer and repeat steps 1 to 7.
If you install the TreeTagger in a different directory, you have to modify the first path in the batch files tag-*.bat using an editor such as Wordpad.
The main issues that occurred during my installation was that I had to re-install Java but once I had done so, it finally worked.
Using the TreeTagger
In this example, we simply implement the TreeTagger without training it! This is in fact not a good practice and should be avoided as I have no way of knowing how good the performance is or what I could do to improve its performance!
# perform POS tagging
set.kRp.env(TT.cmd="C:\\TreeTagger\\bin\\tag-english.bat", lang="en")
postagged <- treetag("D:\\Uni\\UQ\\SLC\\LADAL\\SLCLADAL.github.io\\data\\testcorpus/linguistics07.txt")doc_id | token | tag | lemma | lttr | wclass | desc | stop | stem | idx | sntc |
linguistics07.txt | Related | JJ | related | 7 | adjective | 1 | 1 | |||
linguistics07.txt | areas | NNS | area | 5 | noun | 2 | 1 | |||
linguistics07.txt | of | IN | of | 2 | preposition | 3 | 1 | |||
linguistics07.txt | study | NN | study | 5 | noun | 4 | 1 | |||
linguistics07.txt | also | RB | also | 4 | adverb | 5 | 1 | |||
linguistics07.txt | includes | VVZ | include | 8 | verb | 6 | 1 | |||
linguistics07.txt | the | DT | the | 3 | determiner | 7 | 1 | |||
linguistics07.txt | disciplines | NNS | discipline | 11 | noun | 8 | 1 | |||
linguistics07.txt | of | IN | of | 2 | preposition | 9 | 1 | |||
linguistics07.txt | semiotics | NNS | semiotics | 9 | noun | 10 | 1 |
We can now paste the text and the pos-tags together using the paste function from base R.
postaggedtext <- paste(postagged@tokens$token, postagged@tokens$tag, sep = "/", collapse = " "). |
Related/JJ areas/NNS of/IN study/NN also/RB includes/VVZ the/DT disciplines/NNS of/IN semiotics/NNS (/( the/DT study/NN of/IN direct/JJ and/CC indirect/JJ language/NN through/IN signs/NNS and/CC symbols/NNS )/) ,/, literary/JJ criticism/NN (/( the/DT historical/JJ and/CC ideological/JJ analysis/NN of/IN literature/NN ,/, cinema/NN ,/, art/NN ,/, or/CC published/VVN material/NN )/) ,/, translation/NN (/( the/DT conversion/NN and/CC documentation/NN of/IN meaning/VVG in/IN written/spoken/JJ text/NN from/IN one/CD language/NN or/CC dialect/NN onto/IN another/DT )/) ,/, and/CC speech-language/NN pathology/NN (/( a/DT corrective/JJ method/NN to/TO cure/VV phonetic/JJ disabilities/NNS and/CC dis-functions/NNS at/IN the/DT cognitive/JJ level/NN )/) ./SENT |
POS-Tagging multiple files
To pos-tag several files at once you need to create a list of paths and then apply the treetagger to each of the path elements. Once we have done so, we inspect the structure of the resulting vector which now holds the pos-tagged texts.
corpuspath <- here::here("data/testcorpus")
# generate list of corpus files
corpusfiles <- list.files(corpuspath)
cfiles <- paste0(corpuspath, "/", corpusfiles, sep = "")
# apply treetagger to each file in corpus
postagged_files <- sapply(cfiles, function(x){
set.kRp.env(TT.cmd="C:\\TreeTagger\\bin\\tag-english.bat", lang="en")
x <- treetag(x)
x <- paste(x@tokens$token, x@tokens$tag, sep = "/", collapse = " ")
})
# inspect text.tagged
str(postagged_files)## Named chr [1:7] "Linguistics/NN is/VBZ the/DT scientific/JJ study/NN of/IN language/NN ./SENT It/PP involves/VVZ analysing/VVG l"| __truncated__ ...
## - attr(*, "names")= chr [1:7] "D:/Uni/UQ/SLC/LADAL/SLCLADAL.github.io/data/testcorpus/linguistics01.txt" "D:/Uni/UQ/SLC/LADAL/SLCLADAL.github.io/data/testcorpus/linguistics02.txt" "D:/Uni/UQ/SLC/LADAL/SLCLADAL.github.io/data/testcorpus/linguistics03.txt" "D:/Uni/UQ/SLC/LADAL/SLCLADAL.github.io/data/testcorpus/linguistics04.txt" ...The first pos-tagged corpus file looks like this.
. |
Linguistics/NN is/VBZ the/DT scientific/JJ study/NN of/IN language/NN ./SENT It/PP involves/VVZ analysing/VVG language/NN form/NN language/NN meaning/NN and/CC language/NN in/IN context/NN ./SENT The/DT earliest/JJS activities/NNS in/IN the/DT documentation/NN and/CC description/NN of/IN language/NN have/VHP been/VBN attributed/VVN to/TO the/DT th-century-BC/NN Indian/JJ grammarian/NN Pa/NP ?/SENT ini/NNS who/WP wrote/VVD a/DT formal/JJ description/NN of/IN the/DT Sanskrit/NN language/NN in/IN his/PP$ A/NP ?/SENT ?adhyayi/NNS ./SENT Linguists/NNS traditionally/RB analyse/VVP human/JJ language/NN by/IN observing/VVG an/DT interplay/NN between/IN sound/NN and/CC meaning/NN ./SENT Phonetics/NN is/VBZ the/DT study/NN of/IN speech/NN and/CC non-speech/NN sounds/NNS and/CC delves/VVZ into/IN their/PP$ acoustic/JJ and/CC articulatory/JJ properties/NNS ./SENT The/DT study/NN of/IN language/NN meaning/NN on/IN the/DT other/JJ hand/NN deals/NNS with/IN how/WRB languages/NNS encode/VVP relations/NNS between/IN entities/NNS properties/NNS and/CC other/JJ aspects/NNS of/IN the/DT world/NN to/TO convey/VV process/NN and/CC assign/VV meaning/VVG as/RB well/RB as/RB manage/VV and/CC resolve/VV ambiguity/NN ./SENT While/IN the/DT study/NN of/IN semantics/NN typically/RB concerns/VVZ itself/PP with/IN truth/NN conditions/NNS pragmatics/NN deals/NNS with/IN how/WRB situational/JJ context/NN influences/VVZ the/DT production/NN of/IN meaning/NN ./SENT |
Note that the tag set used for the pos-tagging above differs slightly from the Penn Treebank Tag set. For example, the end of sentences are tagged as SENT rather as PUNC.
POS-Tagging non-English texts
In addition to being very flexible, the TreeTagger is appealing because it supports a comparatively large sample of languages. Here is the list of languages (or varieties) that are currently supported: Bulgarian, Catalan, Chinese, Coptic, Czech, Danish, Dutch, English, Estonian, Finnish, French, Spoken French, Old French, Galician, German, Spoken German, Middle High German, Greek, Ancient Greek, Hausa, Italian, Korean, Latin, Mongolian, Norwegian (Bokmaal), Polish, Portuguese, Romanian, Russian, Slovak, Slovenian, Spanish, Swahili, Swedish.
Unfortunately, not all of these language models are available for R. Currently only language support for English, German, French, Spanish, Italian, and Dutch is currently available via the koRpus package. To be able to use the existing pos-tagging models, you need to download the parameter files as described above and then stored in the lib folder of the TreeTagger folder at the root of your C:/- drive as well as install the respective koRpus.lang models (see below). These models then have to be activated using the library function.
POS-Tagging a German text
# perform POS tagging
set.kRp.env(TT.cmd="C:\\TreeTagger\\bin\\tag-german.bat", lang="de")
postagged_german <- treetag(here::here("data", "german.txt"))doc_id | token | tag | lemma | lttr | wclass | desc | stop | stem | idx | sntc |
german.txt | Sprachwissenschaft | NN | Sprachwissenschaft | 18 | noun | 1 | 1 | |||
german.txt | untersucht | VVFIN | untersuchen | 10 | verb | 2 | 1 | |||
german.txt | in | APPR | in | 2 | preposition | 3 | 1 | |||
german.txt | verschiedenen | ADJA | verschieden | 13 | adjective | 4 | 1 | |||
german.txt | Herangehensweisen | NN | Herangehensweisen | 17 | noun | 5 | 1 | |||
german.txt | die | ART | die | 3 | article | 6 | 1 | |||
german.txt | menschliche | ADJA | menschlich | 11 | adjective | 7 | 1 | |||
german.txt | Sprache | NN | Sprache | 7 | noun | 8 | 1 | |||
german.txt | . | $. | . | 1 | fullstop | 9 | 1 |
The German annotation uses the Stuttgart-Tuebingen tag set (STTS) which is described in great detail here.
POS-Tagging a French text
# perform POS tagging
set.kRp.env(TT.cmd="C:\\TreeTagger\\bin\\tag-french.bat", lang="fr")
postagged_french <- treetag(here::here("data", "french.txt"))doc_id | token | tag | lemma | lttr | wclass | desc | stop | stem | idx | sntc |
french.txt | La | DET:ART | le | 2 | article | 1 | 1 | |||
french.txt | linguistique | ADJ | linguistique | 12 | adjective | 2 | 1 | |||
french.txt | est | VER:pres | être | 3 | verb | 3 | 1 | |||
french.txt | une | DET:ART | un | 3 | article | 4 | 1 | |||
french.txt | discipline | NOM | discipline | 10 | noun | 5 | 1 | |||
french.txt | scientifique | ADJ | scientifique | 12 | adjective | 6 | 1 | |||
french.txt | s’intéressant | VER:ppre | s’intéressant | 13 | verb | 7 | 1 | |||
french.txt | à | PRP | à | 1 | preposition | 8 | 1 | |||
french.txt | l’étude | NOM | l’étude | 7 | noun | 9 | 1 | |||
french.txt | du | PRP:det | du | 2 | preposition | 10 | 1 |
The tag set used for pos-tagging French texts is described here and summarized below.
POS-Tagging a Spanish text
# perform POS tagging
set.kRp.env(TT.cmd="C:\\TreeTagger\\bin\\tag-spanish.bat", lang="es")
postagged_spanish <- treetag(here::here("data", "spanish.txt"))doc_id | token | tag | lemma | lttr | wclass | desc | stop | stem | idx | sntc |
spanish.txt | La | ART | el | 2 | determiner | 1 | 1 | |||
spanish.txt | lingüística | NC | lingüística | 11 | noun | 2 | 1 | |||
spanish.txt | es | VSfin | ser | 2 | verb | 3 | 1 | |||
spanish.txt | el | ART | el | 2 | determiner | 4 | 1 | |||
spanish.txt | estudio | NC | estudio | 7 | noun | 5 | 1 | |||
spanish.txt | científico | ADJ | científico | 10 | adjective | 6 | 1 | |||
spanish.txt | del | PDEL | del | 3 | del | 7 | 1 | |||
spanish.txt | origen | NC | origen | 6 | noun | 8 | 1 | |||
spanish.txt | , | CM | , | 1 | comma | 9 | 1 | |||
spanish.txt | la | ART | el | 2 | determiner | 10 | 1 |
The tag set used for pos-tagging Spanish texts is described here and summarized below.
POS-Tagging an Italian text
# perform POS tagging
set.kRp.env(TT.cmd="C:\\TreeTagger\\bin\\tag-italian.bat", lang="it")
postagged_italian <- treetag(here::here("data", "italian.txt"))doc_id | token | tag | lemma | lttr | wclass | desc | stop | stem | idx | sntc |
italian.txt | La | DET:def | il | 2 | determiner | 1 | 1 | |||
italian.txt | linguistica | NOM | linguistica | 11 | noun | 2 | 1 | |||
italian.txt | è | VER:pres | essere | 1 | verb | 3 | 1 | |||
italian.txt | lo | DET:def | il | 2 | determiner | 4 | 1 | |||
italian.txt | studio | NOM | studio | 6 | noun | 5 | 1 | |||
italian.txt | scientifico | ADJ | scientifico | 11 | adjective | 6 | 1 | |||
italian.txt | del | PRE:det | del | 3 | preposition | 7 | 1 | |||
italian.txt | linguaggio | NOM | linguaggio | 10 | noun | 8 | 1 | |||
italian.txt | verbale | ADJ | verbale | 7 | adjective | 9 | 1 | |||
italian.txt | umano | ADJ | umano | 5 | adjective | 10 | 1 |
The tag set used for pos-tagging Italian texts is described here and summarized below.
POS-Tagging a Dutch text
# perform POS tagging
set.kRp.env(TT.cmd="C:\\TreeTagger\\bin\\tag-dutch.bat", lang="nl")
postagged_dutch <- treetag(here::here("data", "dutch.txt"))doc_id | token | tag | lemma | lttr | wclass | desc | stop | stem | idx | sntc |
dutch.txt | Taalkunde | nounsg | taalkunde | 9 | noun | 1 | 1 | |||
dutch.txt | , | punc | , | 1 | punctuation | 2 | 1 | |||
dutch.txt | ook | adv | ook | 3 | adverb | 3 | 1 | |||
dutch.txt | wel | adv | wel | 3 | adverb | 4 | 1 | |||
dutch.txt | taalwetenschap | nounsg | taalwetenschap | 14 | noun | 5 | 1 | |||
dutch.txt | of | conjcoord | of | 2 | conjunction | 6 | 1 | |||
dutch.txt | linguïstiek | nounsg | linguïstiek | 11 | noun | 7 | 1 | |||
dutch.txt | , | punc | , | 1 | punctuation | 8 | 1 | |||
dutch.txt | is | verbpressg | zijn | 2 | verb | 9 | 1 | |||
dutch.txt | de | det__art | de | 2 | determiner | 10 | 1 |
The tag set used for pos-tagging Dutch texts is available here and summarized below.
4 POS-Tagging with coreNLP
Another package that is very handy when it comes to pos-tagging but more importantly syntactic parsing is the coreNLP package (see Arnold and Tilton 2015).
NOTE
Unfortunately, we cannot use it at this point as my machine runs out of memory when I try running the code below.
options(java.parameters = "-Xmx4096m")
initCoreNLP(mem = "8g")
# annotate
annotation <- annotateString(text)
annotation5 Syntactic Parsing
Parsing refers to another type of annotation in which either structural information (as in the case of XML documents) or syntactic relations are added to text. As syntactic parsing is commonly more relevant in the language sciences, the following will focus only on syntactic parsing. syntactic parsing builds on pos-tagging and allows drawing syntactic trees or dependencies. Unfortunately, syntactic parsing still has relatively high error rates when dealing with language that is not very formal. However, syntactic parsing is very reliable when dealing with written language.
text <- readLines("https://slcladal.github.io/data/english.txt")
# convert character to string
s <- as.String(text)
# define sentence and word token annotator
sent_token_annotator <- openNLP::Maxent_Sent_Token_Annotator()
word_token_annotator <- openNLP::Maxent_Word_Token_Annotator()
# apply sentence and word annotator
a2 <- NLP::annotate(s, list(sent_token_annotator, word_token_annotator))
# define syntactic parsing annotator
parse_annotator <- openNLP::Parse_Annotator()
# apply parser
p <- parse_annotator(s, a2)
# extract parsed information
ptexts <- sapply(p$features, '[[', "parse")
ptexts## [1] "(TOP (S (S (NP (NNP Linguistics)) (VP (VBZ is) (NP (NP (DT the) (JJ scientific) (NN study)) (PP (IN of) (NP (NN language)))))) (CC and) (S (NP (PRP it)) (VP (VBZ involves) (NP (NP (NP (DT the) (NN analysis)) (PP (IN of) (NP (NN language) (NN form))))(, ,) (NP (NN language) (NN meaning))(, ,) (CC and) (NP (NP (NN language)) (PP (IN in) (NP (NN context)))))))(. .)))"# read into NLP Tree objects.
ptrees <- lapply(ptexts, Tree_parse)
# show frist tree
ptrees[[1]]## (TOP
## (S
## (S
## (NP (NNP Linguistics))
## (VP
## (VBZ is)
## (NP
## (NP (DT the) (JJ scientific) (NN study))
## (PP (IN of) (NP (NN language))))))
## (CC and)
## (S
## (NP (PRP it))
## (VP
## (VBZ involves)
## (NP
## (NP
## (NP (DT the) (NN analysis))
## (PP (IN of) (NP (NN language) (NN form))))
## (, ,)
## (NP (NN language) (NN meaning))
## (, ,)
## (CC and)
## (NP (NP (NN language)) (PP (IN in) (NP (NN context)))))))
## (. .)))These trees can, of course, also be shown visually, for instance, in the form of a syntax trees (or tree dendrogram).
# generate syntax tree
parse2graph(ptexts[1], leaf.color='red',
# to put sentence in title (not advisable for long sentences)
#title = stringr::str_squish(stringr::str_remove_all(ptexts[1], "\\(\\,{0,1}[A-Z]{0,4}|\\)")),
margin=-0.05,
vertex.color=NA,
vertex.frame.color=NA,
vertex.label.font=2,
vertex.label.cex=.75,
asp=.8,
edge.width=.5,
edge.color='gray',
edge.arrow.size=0)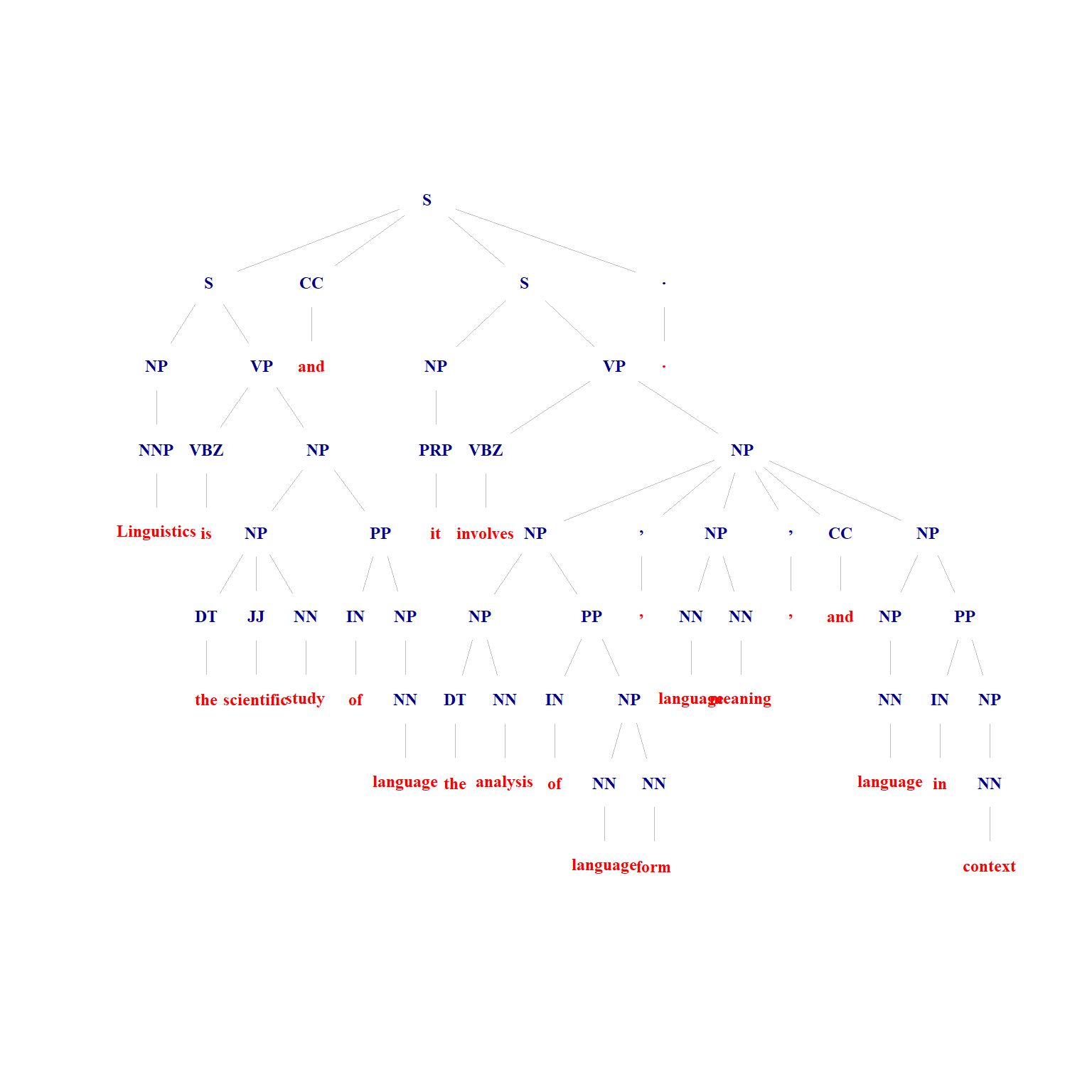
Syntax trees are very handy because the allow us to check how reliable the parser performed.
We can use the get_phrase_type_regex function from the parsent package written by Tyler Rinker to extract phrases from the parsed tree.
pacman::p_load_gh(c("trinker/textshape", "trinker/parsent"))
nps <- get_phrase_type_regex(ptexts[1], "NP") %>%
unlist()
# inspect
nps## [1] "(NP (NNP Linguistics))"
## [2] "(NP (NP (DT the) (JJ scientific) (NN study)) (PP (IN of) (NP (NN language))))"
## [3] "(NP (PRP it))"
## [4] "(NP (NP (NP (DT the) (NN analysis)) (PP (IN of) (NP (NN language) (NN form))))(, ,) (NP (NN language) (NN meaning))(, ,) (CC and) (NP (NP (NN language)) (PP (IN in) (NP (NN context)))))"We can now extract the leaves from the text to get the parsed object.
nps_text <- stringr::str_squish(stringr::str_remove_all(nps, "\\(\\,{0,1}[A-Z]{0,4}|\\)"))
# inspect
nps_text## [1] "Linguistics"
## [2] "the scientific study of language"
## [3] "it"
## [4] "the analysis of language form , language meaning , and language in context"Unfortunately, we can only extract top level phrases (the NPs with the NPs are npt extracted separately).
In order to extract all phrases, we can use the phrasemachine from the CRAN archive.
We now load the phrasemachine package and pos-tag the text(s) (we will simply re-use the English text we pos-tagged before.)
# pos tag text
tagged_documents <- phrasemachine::POS_tag_documents(text)## Currently tagging document 1 of 1# inspect
tagged_documents## $Document_1
## $Document_1$tokens
## [1] "Linguistics" "is" "the" "scientific" "study"
## [6] "of" "language" "and" "it" "involves"
## [11] "the" "analysis" "of" "language" "form"
## [16] "," "language" "meaning" "," "and"
## [21] "language" "in" "context" "."
##
## $Document_1$tags
## [1] "NNP" "VBZ" "DT" "JJ" "NN" "IN" "NN" "CC" "PRP" "VBZ" "DT" "NN"
## [13] "IN" "NN" "NN" "," "NN" "NN" "," "CC" "NN" "IN" "NN" "."In a next step, we can use the extract_phrases function to extract phrases.
#extract phrases
phrases <- phrasemachine::extract_phrases(tagged_documents,
regex = "(A|N)*N(PD*(A|N)*N)*",
maximum_ngram_length = 8,
minimum_ngram_length = 1)## Extracting phrases from document 1 of 1# inspect
phrases## [[1]]
## [1] "Linguistics" "scientific_study"
## [3] "scientific_study_of_language" "study"
## [5] "study_of_language" "language"
## [7] "analysis" "analysis_of_language"
## [9] "analysis_of_language_form" "language"
## [11] "language_form" "form"
## [13] "language" "language_meaning"
## [15] "meaning" "language"
## [17] "language_in_context" "context"Now, we have all noun phrases that occur in the English sample text.
Citation & Session Info
Schweinberger, Martin. 2021. POS-Tagging and Syntactic Parsing with R. Brisbane: The University of Queensland. url: https://slcladal.github.io/tagging.html (Version 2021.10.01).
@manual{schweinberger2021pos,
author = {Schweinberger, Martin},
title = {pos-Tagging and Syntactic Parsing with R},
note = {https://slcladal.github.io/tagging.html},
year = {2021},
organization = "The University of Queensland, School of Languages and Cultures},
address = {Brisbane},
edition = {2021.10.01}
}sessionInfo()## R version 4.1.1 (2021-08-10)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 19043)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=German_Germany.1252 LC_CTYPE=German_Germany.1252
## [3] LC_MONETARY=German_Germany.1252 LC_NUMERIC=C
## [5] LC_TIME=German_Germany.1252
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] parsent_0.1.0 textshape_1.7.4 flextable_0.6.8
## [4] phrasemachine_1.1.2 koRpus.lang.ru_0.1-2 koRpus.lang.pt_0.1-3
## [7] koRpus.lang.fr_0.1-2 koRpus.lang.it_0.1-2 koRpus.lang.nl_0.1-5
## [10] koRpus.lang.es_0.1-2 koRpus.lang.de_0.1-2 koRpus.lang.en_0.1-4
## [13] koRpus_0.13-8 sylly_0.1-6 coreNLP_0.4-2
## [16] openNLPdata_1.5.3-4 openNLP_0.2-7 tm_0.7-8
## [19] NLP_0.2-1 igraph_1.2.6 forcats_0.5.1
## [22] stringr_1.4.0 dplyr_1.0.7 purrr_0.3.4
## [25] readr_2.0.1 tidyr_1.1.3 tibble_3.1.4
## [28] ggplot2_3.3.5 tidyverse_1.3.1 DT_0.19
##
## loaded via a namespace (and not attached):
## [1] colorspace_2.0-2 ellipsis_0.3.2 coreNLPsetup_0.0.1 rprojroot_2.0.2
## [5] base64enc_0.1-3 fs_1.5.0 sylly.pt_0.1-2 rstudioapi_0.13
## [9] fansi_0.5.0 lubridate_1.7.10 xml2_1.3.2 knitr_1.34
## [13] jsonlite_1.7.2 rJava_1.0-5 broom_0.7.9 dbplyr_2.1.1
## [17] compiler_4.1.1 httr_1.4.2 backports_1.2.1 assertthat_0.2.1
## [21] Matrix_1.3-4 fastmap_1.1.0 cli_3.0.1 htmltools_0.5.2
## [25] tools_4.1.1 gtable_0.3.0 glue_1.4.2 Rcpp_1.0.7
## [29] sylly.it_0.1-2 slam_0.1-48 cellranger_1.1.0 jquerylib_0.1.4
## [33] vctrs_0.3.8 crosstalk_1.1.1 xfun_0.26 sylly.fr_0.1-2
## [37] rvest_1.0.1 lifecycle_1.0.1 pacman_0.5.1 XML_3.99-0.8
## [41] klippy_0.0.0.9500 scales_1.1.1 hms_1.1.0 parallel_4.1.1
## [45] sylly.es_0.1-2 yaml_2.2.1 gdtools_0.2.3 stringi_1.7.4
## [49] highr_0.9 zip_2.2.0 sylly.ru_0.1-2 sylly.en_0.1-3
## [53] rlang_0.4.11 pkgconfig_2.0.3 systemfonts_1.0.2 evaluate_0.14
## [57] lattice_0.20-44 htmlwidgets_1.5.4 tidyselect_1.1.1 here_1.0.1
## [61] sylly.de_0.1-2 magrittr_2.0.1 R6_2.5.1 generics_0.1.0
## [65] DBI_1.1.1 pillar_1.6.3 haven_2.4.3 withr_2.4.2
## [69] modelr_0.1.8 crayon_1.4.1 uuid_0.1-4 utf8_1.2.2
## [73] tzdb_0.1.2 rmarkdown_2.5 officer_0.4.0 grid_4.1.1
## [77] readxl_1.3.1 data.table_1.14.0 reprex_2.0.1.9000 digest_0.6.27
## [81] sylly.nl_0.1-2 munsell_0.5.0References
Arnold, Taylor, and Lauren Tilton. 2015. Humanities Data in R: Exploring Networks, Geospatial Data, Images, and Text. Cham: Springer.
Kumar, Ashish, and Avinash Paul. 2016. Mastering Text Mining with R. Packt Publishing Ltd.
Wiedemann, Gregor, and Andreas Niekler. 2017. “Hands-on: A Five Day Text Mining Course for Humanists and Social Scientists in R.” In Proceedings of the Workshop on Teaching NLP for Digital Humanities (Teach4DH2017), Berlin, Germany, September 12, 2017., 57–65. http://ceur-ws.org/Vol-1918/wiedemann.pdf.