Creating Vowel Charts in R
Martin Schweinberger
2021-09-29

Introduction
This tutorial exemplifies how to create a vowel chart with Praat and R. The entire R markdown document for this tutorial can be downloaded here.
As part of this tutorial are based on R, you need to install and load certain packages to visualize the data later on.
Preparation and session set up
This tutorial is based on R. If you have not installed R or are new to it, you will find an introduction to and more information how to use R here. For this tutorials, we need to install certain packages from an R library so that the scripts shown below are executed without errors. Before turning to the code below, please install the packages by running the code below this paragraph. If you have already installed the packages mentioned below, then you can skip ahead and ignore this section. To install the necessary packages, simply run the following code - it may take some time (between 1 and 5 minutes to install all of the packages so you do not need to worry if it takes some time).
# install packages
install.packages("vowels")
install.packages("tidyverse")
install.packages("flextable")
# install klippy for copy-to-clipboard button in code chunks
remotes::install_github("rlesur/klippy")We now load the packages.
# load packages
library(tidyverse)
library(vowels)
library(flextable)
# activate klippy for copy-to-clipboard button
klippy::klippy()Once you have installed R and RStudio and once you have also initiated the session by executing the code shown above, you are good to go.
Vowel sounds
When learning or studying a language - the case in point here being English - it is likely that you are confronted with different classes of sounds, e.g. consonants and vowels (Rogers 2014). Consonants differ from vowels in that they are formed with an obstruction of the air stream coming from the lungs and they cannot form the nucleus of a syllable (Zsiga 2012). In fact, consonants are classified according to the manner and place of the obstruction of the air stream. As vowels are produced without obstruction of the air stream, other criteria for differentiating between vowel sounds are needed. The criteria for differentiating between different vowel sounds are
the number of tongue positions during vowel production (to differentiate between mono-, diph-, and triphthongs),
height of the tongue,
position of the tongue,
roundedness of the lips.
The latter two features are used in the production of vowel charts which show where in the mouth the tongue is located during the production of monophthongal vowel phones. A vowel chart for the monophthongal vowel phones in Received Pronunciation (RP) is shown below.
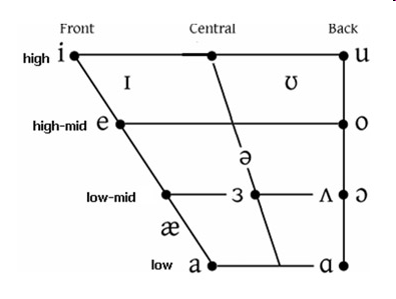
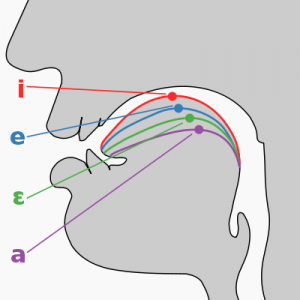
Figure 1: Vowel Chart of monophthongal vowel sounds in Received Pronunciation (RP) (left); Tongue positions for the vowels /i, e, E, a/ (right)
Interestingly, a very similar figure can be created by plotting the Hertz frequency of the first formant of monophthongal vowel sound against the Hertz frequency of second formant minus the Hertz frequency of the first formant of a monophthongal vowel sound. Formants are frequencies of air waves that, if collapsed, form a complex vowel sound (Johnson 2003; Ladefoged 1996). In other words, vowels are periodic, i.e. rythmic, compressions and decompressions of air and to create a vowel sound, i.e. a complex periodic wave, one needs to produce several simple periodic waves simultaneously. During acoustic analysis, the complex wave is deconstructed into its component parts, i.e. the simple periodic waves that make up that sound. This means that we do not necessarily have to plot the position of the tongue of a speaker when he or she produces vowels to create a vowel chart but that analyses of audio recordings of words in which vowels occur, can be utilized to plot a personalized vowel chart of a speaker. Such vowel charts can then be used in language learning as corrective feedback (see Paganus et al. 2006).
To produce a personalized vowel chart, the following steps are necessary:
Install Praat
Record words in which all monophthongal vowel sounds of a given variety occur;
Measure and extract the first and second formant of each vowel;
Visualize the vowel sounds.
The subsequent sections elaborate the above steps. However, before continuing a word of warning is in order. The example focuses on extracting and plotting vowel formants in an easy but also very uncontrolled way. In case vowel formant extraction is part of a proper research project, some additional steps are warranted. For instance, in a serious research project, it were necessary to control and reduce environmental noise and to optimize the recording situation, one would have to randomize the test items (words with the required phonetic environment and the respective vowel sounds) and use filler items (words that are not relevant for the analysis proper) in order to avoid participants guessing which items are relevant for the analysis, one would also use text grids in Praat to guarantee replicability instead of the simple measurements we use in the example here, etc. However, in case you are only interested in an approximation of your own vowel production and how native-like it is, the example fulfills its purpose and provides the reader with a step-by-step guide on how to plot your personalized vowel chart.
Downloading and installing PRAAT The first step is thus to download Praat form www.praat.org and to install it on your machine by following the instructions provided on the website and by the Praat installation script. Praat is an open{source software for acoustic analysis that was developed by Paul Boersma at the University of Amsterdam.
After having installed Praat we need to record the words in which the monophthongal vowel phones occur. In this example, we will simply record the words shown below.
word | ipa_symbols | phonemic_context |
had | æ | h_d |
hard | ɑ | h_d |
head | e | h_d |
heed | i | h_d |
herd | ɜ | h_d |
hid | ɪ | h_d |
hoard | ɔ | h_d |
hod | ɒ | h_d |
hood | ʊ | h_d |
hud | ʌ | h_d |
who'd | u | h_d |
The following section describes how to record data in Praat (see Styler 2013 for a more elaborate description of how this can be done).
1 Recording words in PRAAT
To record these words, start Praat with a double click on the Praat symbol which - after intstallation - appears on your Desktop. Two windows will appear: the main object window to the left and the picture window to the right (cf. Figure 2). Close the picture window on the right and choose New from the menu at the top of the main object window and select Record mono sound from the menu which pops up. For the recording it is, of course, necessary that a microphone is hook up to your machine { the better the microphone, the better the recording and thus the more accurate the graphical display we are going to produce.
Figure 2: Praat’s main object window (left) and Praat’s picture window (right)
Selecting Record mono sound opens Praat’s SoundRecorder window (cf. Figure 4). Select Record, label the recording by entering a title, e.g. vowels, in the Name field and read the words form the list shown in Table .
Figure 3: Praat’s main object window
Figure 4: Praat’s recording window
Each word should be repeated at least three times with a short break between the individual items so that what you record is had, had, had … pause … hard, hard, hard, etc. Try to sound natural, i.e. avoid speaking too fast or too slow, and try not to sound artificial or too careful.
While recording, there should be some green bouncing up and down in the vertical white " stripe (no bouncing indicates that your machine is not recording properly from the microphone).Once you are finished with your recording, select Stop and next select Save to list & close (cf. Figure 8).
Figure 5: Praat’s recording window during recording
Figure 6: Praat’s recording window after recording
Saving has created an object in Praat’s main object window - in case you have named your recording vowels, the new object will be called 1. Sound vowels (cf. Figure 7). Before editing the data, it is advisable to save them on your machine. To save the data select the Save option from the upper menu, then select Save as WAV file... and navigate to the directory in which you want to save the recorded data.
Figure 7: Praat’s main object window with saved object
Figure 8: Save the recording as a .wav file
Next, select View & Edit in Praat’s main menu in the main object window. This will open Praat’s edit window (cf. Figure 9) - the object represents a recording of the word heed repeated three times for sake of simplicity.
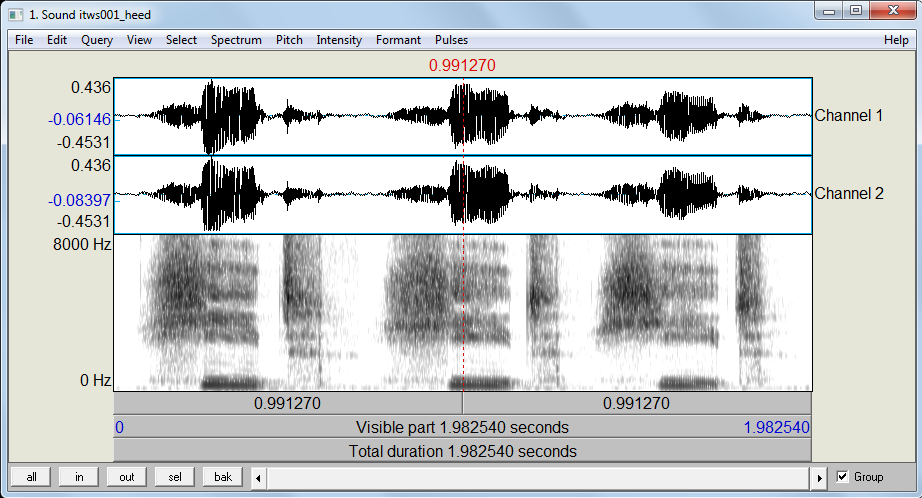
Figure 9: Praat’s edit window with the word heed repeated three times
After recording and saving the data necessary for the task at hand, we continue by extracting the vowel formants.
2 Measure and extract vowel formants
Before extracting of the vowel formants, some parameters need adjusting. In a first step, go to Formant from the menu at the top of the edit window and select Formant settings.... Next, select the option Show formant and then, depending on whether the recording represents a male, a female or a child, adjust the Maximum formant (Hz) to 5000 Hz (male), 5500 Hz (female) or up to 8000 Hz (for a child) (cf. http://www.haskins.yale.edu/staff/gafos_ downloads/AcouToyPraat(1).pdf). It may also be necessary to adjust the number of formants that Praat aims to find: the default is 5, but it may be set to any number between 3 and 7 depending on the data. To elaborate, if the formants do not exhibit a regular horizontal pattern but they are somewhat unsteady or the dots are all over the place, try to find the number of formants that provide the best results (i.e. steady horizontal lines).
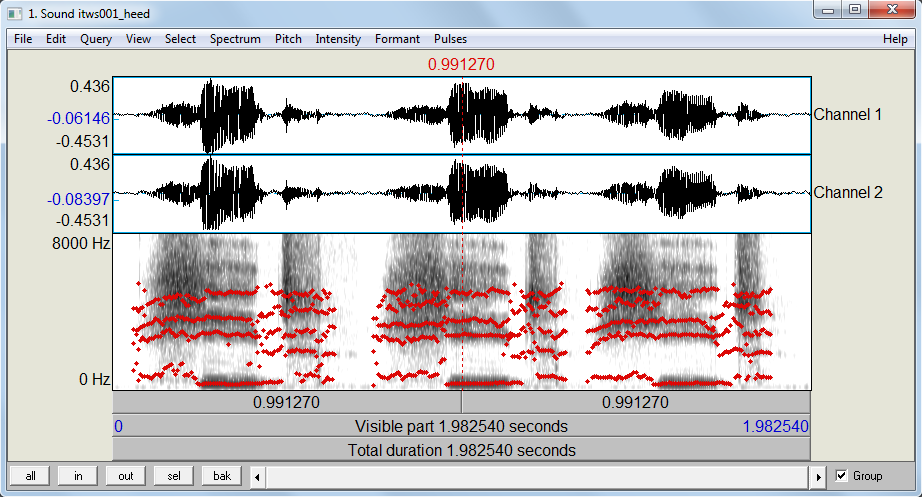
Figure 10: Praat’s edit window with the word heed repeated three times and formants shown
After having set the parameters, listen to the recording and highlight the section which represents the vowel sound you want to extract the formants from. Highlightling is done by selecting the start and end point of the vowel sound - the beginning and end of the steady line during which the vowel is produced - within the edit window as done for the first of the three instances of heed in Figure 11.
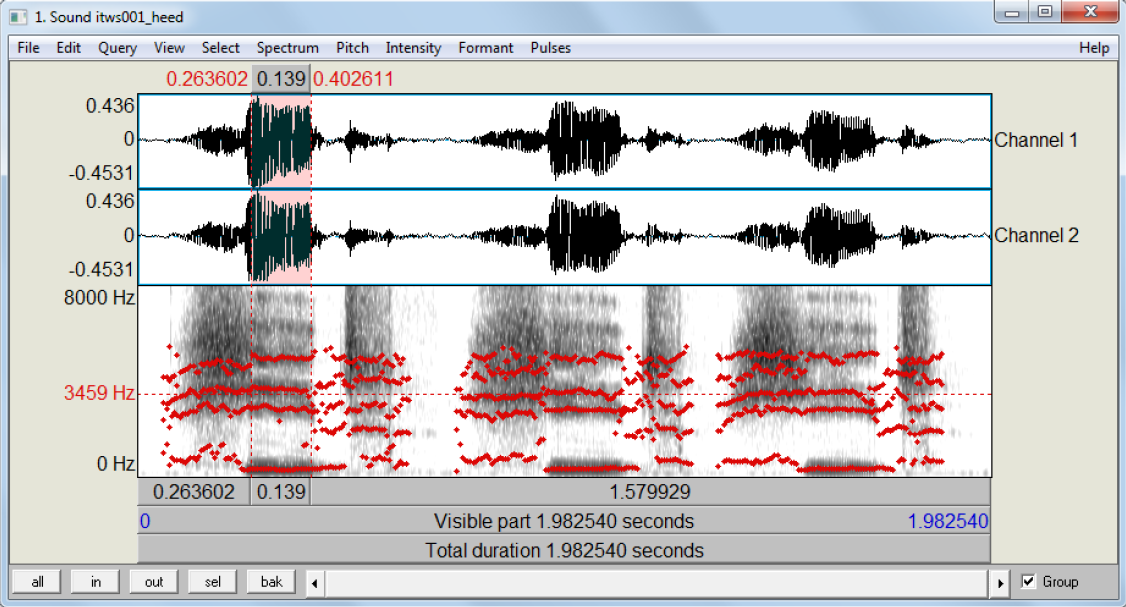
Figure 11: Praat’s edit window with the word heed repeated three times and formants shown and steady state selected
The vowel formants can be extracted by going to Formant in the edit window and selecting Get first formant. Having done so, a window with the mean Hertz frequency of the first formant during the steady state is shown (cf. Figure 12). Please note that you should additionally extract the start and end time of the highlighted section from the display in the edit window.
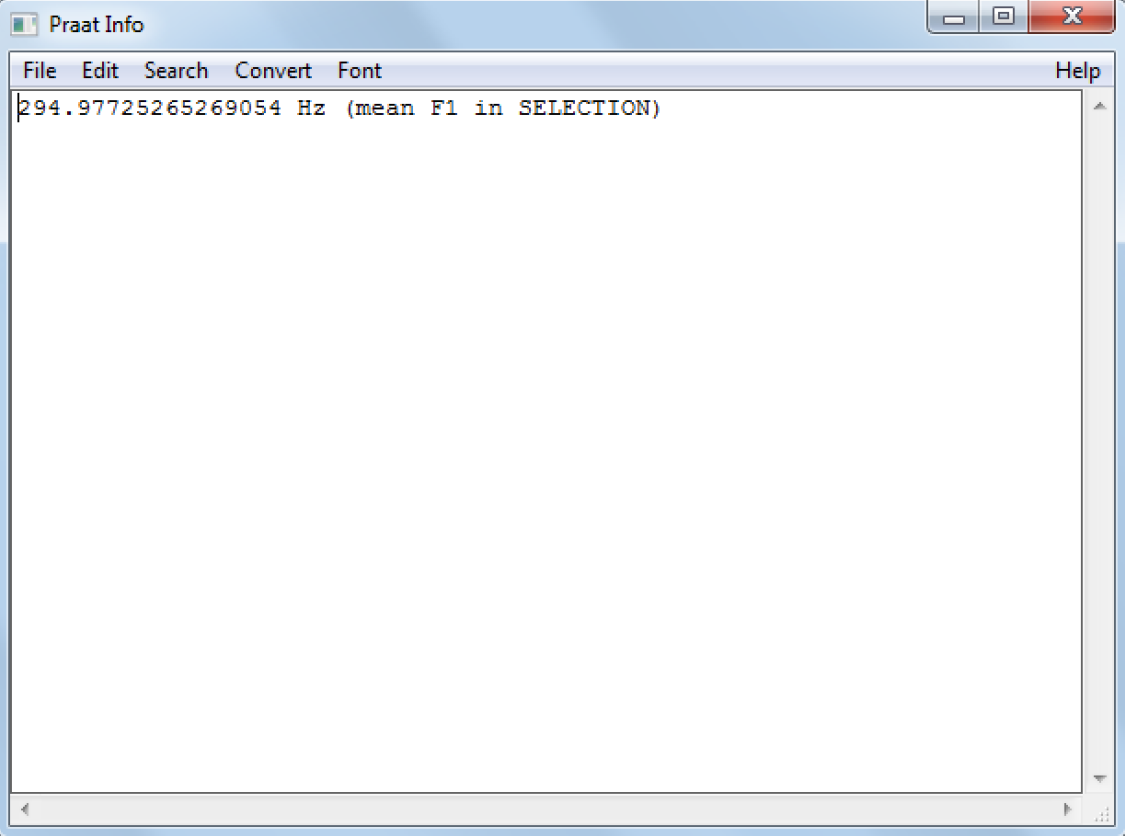
Figure 12: The mean Hertz frequency of first formant of the word heed during the steady state
To extract the second (and in case you want to use your data in other analysis also the third formant) simply choose Get third formant (and Get second formant), note down the Hertz frequencies in a table, and also note down the start and end time of the steady state. The final table should look like Table below (some columns are removed for sake of simplicity).
file | subject | trial | item | F1 | F2 |
vowels | ms | 1 | had | 717.3361 | 1,868.1754 |
vowels | ms | 1 | had | 743.4835 | 1,903.7152 |
vowels | ms | 1 | had | 720.9740 | 1,938.6928 |
vowels | ms | 1 | hard | 734.5275 | 1,493.3289 |
vowels | ms | 1 | hard | 832.9228 | 1,407.8247 |
vowels | ms | 1 | hard | 797.2842 | 1,498.2064 |
vowels | ms | 1 | head | 610.8943 | 2,062.8820 |
vowels | ms | 1 | head | 722.2519 | 2,130.6322 |
vowels | ms | 1 | head | 625.1117 | 2,009.6507 |
vowels | ms | 1 | heed | 263.3830 | 2,833.0017 |
vowels | ms | 1 | heed | 301.4176 | 2,745.8471 |
vowels | ms | 2 | heed | 286.9656 | 2,822.5988 |
vowels | ms | 2 | herd | 532.7925 | 1,704.9954 |
vowels | ms | 2 | herd | 537.7962 | 1,819.8916 |
vowels | ms | 2 | herd | 524.7137 | 1,704.2321 |
vowels | ms | 2 | hid | 451.8766 | 2,390.7996 |
vowels | ms | 2 | hid | 417.0330 | 2,483.3900 |
vowels | ms | 2 | hid | 410.6817 | 2,360.0382 |
vowels | ms | 2 | hoard | 540.3306 | 951.1443 |
vowels | ms | 2 | hoard | 549.9205 | 927.0956 |
vowels | ms | 2 | hoard | 648.0482 | 1,093.3466 |
vowels | ms | 2 | hod | 698.4069 | 1,144.4669 |
vowels | ms | 3 | hod | 615.1621 | 1,086.4479 |
vowels | ms | 3 | hod | 751.0190 | 1,452.4663 |
vowels | ms | 3 | hood | 431.2993 | 1,478.1930 |
vowels | ms | 3 | hood | 404.1884 | 1,453.1036 |
vowels | ms | 3 | hood | 470.1469 | 1,216.3027 |
vowels | ms | 3 | hud | 646.0514 | 1,700.0030 |
vowels | ms | 3 | hud | 622.5302 | 1,510.4514 |
vowels | ms | 3 | hud | 749.3540 | 1,581.7578 |
vowels | ms | 3 | whod | 346.8812 | 1,013.0007 |
vowels | ms | 3 | whod | 353.8265 | 1,285.8341 |
vowels | ms | 3 | whod | 366.8137 | 1,016.9800 |
The next section describes how to plot the data and compare the vowels to equivalent vowels produced by native-RP speakers.
3 Visualizing the vowel sounds
We will now process the data so that we can plot the F1 against the F2 values by speaker and word. In a first step, we load the data from the learner (nns) and the native speakers (ns).
# load data
ns <- read.table("https://slcladal.github.io/data/rpvowels.txt", header = T, sep = "\t")
nns <- read.table("https://slcladal.github.io/data/vowels.txt", header = T, sep = "\t") %>%
dplyr::select(-file)The data of the native speakers, i.e the reference data, is shown below.
subject | item | context | F1 | F2 | F1sd | F2sd |
rpspk | had | wordlist | 916.35 | 1,473.15 | 124.29815 | 119.43696 |
rpspk | hard | wordlist | 604.15 | 1,040.15 | 70.91973 | 40.06478 |
rpspk | head | wordlist | 599.95 | 1,925.70 | 102.22858 | 143.60476 |
rpspk | heed | wordlist | 276.15 | 2,337.60 | 25.48328 | 223.42440 |
rpspk | herd | wordlist | 493.55 | 1,372.40 | 47.40917 | 95.94648 |
rpspk | hid | wordlist | 392.85 | 2,174.35 | 40.83893 | 166.85868 |
rpspk | hoard | wordlist | 391.65 | 629.60 | 39.70718 | 81.19074 |
rpspk | hod | wordlist | 483.10 | 864.90 | 35.48002 | 48.49948 |
rpspk | hood | wordlist | 412.85 | 1,286.65 | 32.98209 | 193.69870 |
rpspk | hud | wordlist | 658.20 | 1,208.05 | 116.14945 | 72.51677 |
rpspk | whod | wordlist | 288.70 | 1,616.30 | 30.18905 | 225.73858 |
The reference data is taken from from Hawkins and Midgley (2005) (see here) and represents the first and second formant for the words heed, hid, head, had, hard, hod, hoard, hood, who’d, hud, and herd produced by 5 20 to 25 year old L1-speakers of Received Pronunciation.
We now combine the two data sets, rename the subject and item columns to Speaker and Word, add a column which holds the ipa symbols of the vowel sounds that the word represent, and we calculate the means of the F1 (F1_mean) and F2 (F2_mean) by Word and Speaker.
Speaker | Word | F1 | F2 | ipa | F1_mean | F2_mean |
Learner | had | 717.3361 | 1,868.175 | æ | 727.2645 | 1,903.528 |
Learner | had | 743.4835 | 1,903.715 | æ | 727.2645 | 1,903.528 |
Learner | had | 720.9740 | 1,938.693 | æ | 727.2645 | 1,903.528 |
Learner | hard | 734.5275 | 1,493.329 | ɑ | 788.2448 | 1,466.453 |
Learner | hard | 832.9228 | 1,407.825 | ɑ | 788.2448 | 1,466.453 |
Learner | hard | 797.2842 | 1,498.206 | ɑ | 788.2448 | 1,466.453 |
Learner | head | 610.8943 | 2,062.882 | e | 652.7526 | 2,067.722 |
Learner | head | 722.2519 | 2,130.632 | e | 652.7526 | 2,067.722 |
Learner | head | 625.1117 | 2,009.651 | e | 652.7526 | 2,067.722 |
Learner | heed | 263.3830 | 2,833.002 | i | 283.9220 | 2,800.483 |
Learner | heed | 301.4176 | 2,745.847 | i | 283.9220 | 2,800.483 |
Learner | heed | 286.9656 | 2,822.599 | i | 283.9220 | 2,800.483 |
Learner | herd | 532.7925 | 1,704.995 | ɜ | 531.7675 | 1,743.040 |
Learner | herd | 537.7962 | 1,819.892 | ɜ | 531.7675 | 1,743.040 |
Learner | herd | 524.7137 | 1,704.232 | ɜ | 531.7675 | 1,743.040 |
We can now generate the vowel chart by plotting the F1 values against the F2 values. In addition, we will differentiate between different vowel sounds as well as between the learner (Learner) and native speakers (NS).
ns <- voweldata %>% dplyr::filter(Speaker == "NS")
nns <- voweldata %>% dplyr::filter(Speaker == "Learner")
ggplot(voweldata, aes(F2, F1, color = Speaker, group = Word, fill = Speaker)) +
geom_point(alpha = .1) +
geom_text(data = voweldata, aes(x = F2_mean, y = F1_mean, label = ipa), fontface = "bold") +
stat_ellipse(data = ns, level = 0.50, geom = "polygon", alpha = 0.05, aes(fill = Speaker)) +
stat_ellipse(data = nns, level = 0.95, geom = "polygon", alpha = 0.05, aes(fill = Speaker)) +
scale_x_reverse(breaks = seq(500, 3000, 500), labels = seq(500, 3000, 500)) + scale_y_reverse() +
scale_color_manual(breaks = c("Learner", "NS"), values = c("orange", "gray40")) +
theme_bw() +
theme(legend.position = "top",
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())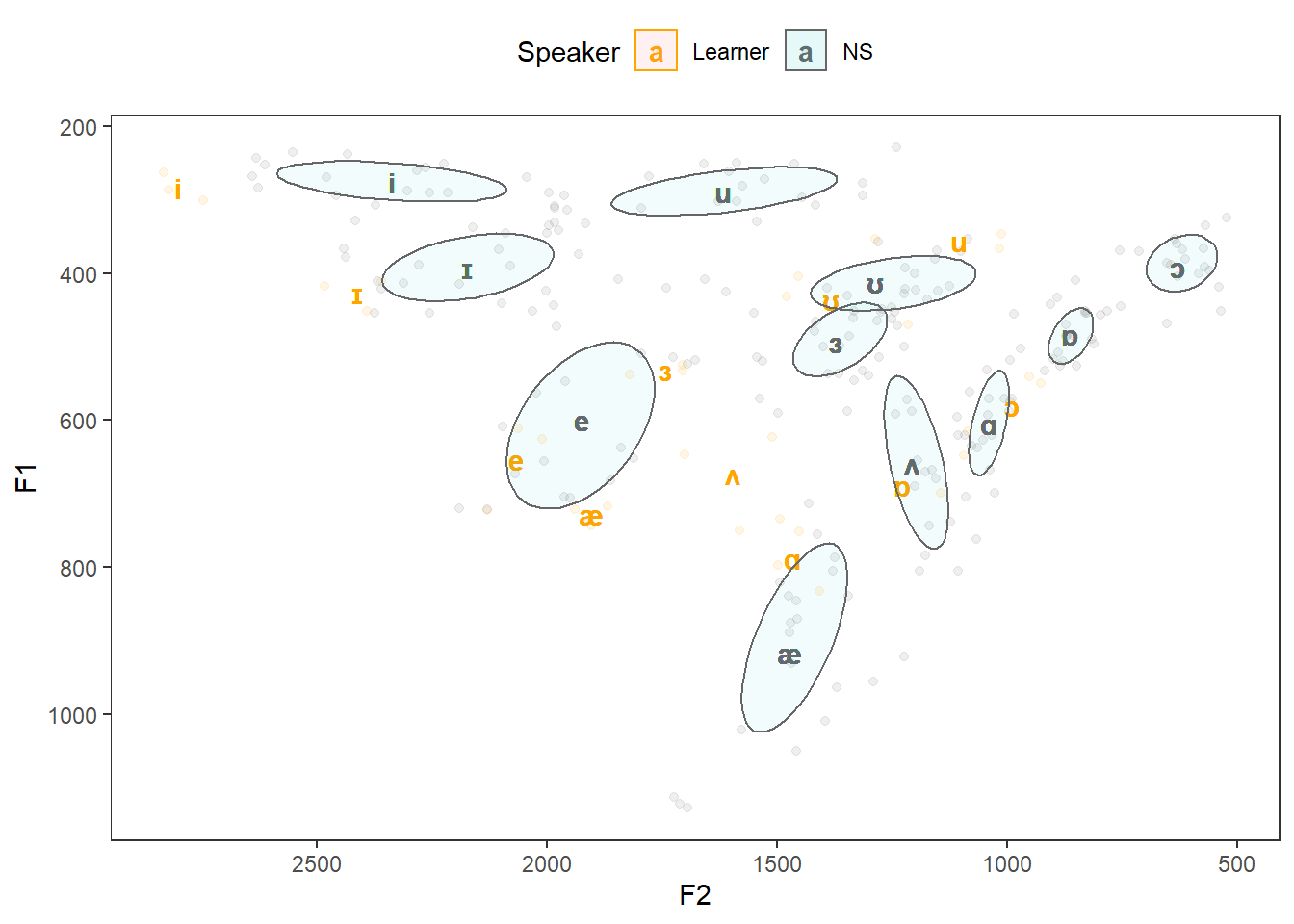
The vowel chart shows that the i-sounds by the L1-German speaker are more fronted and that the o-sounds are substantially higher by the non-native speaker compared to the RP reference vowel spaces. The short u-sound, however, is very similar, indicating that this L1-German speaker produces the short u-sound in English very native-like while the long u-sound is higher and more fronted in the speech of the L1-German speaker. Interestingly, the vowel space of the ash differs quite dramatically between the native speakers and the L1 German speaker which could be caused by the fact that German does not have an ash vowel. I hope this short tutorial helps you in creating your own personalized vowel charts with Praat and R.
Citation & Session Info
Schweinberger, Martin. 2021. Creating Vowel Charts in R. Brisbane: The University of Queensland. url: https://slcladal.github.io/vc.html (Version 2021.09.29).
@manual{schweinberger2021vc,
author = {Schweinberger, Martin},
title = {Creating Vowel Charts in R},
note = {https://slcladal.github.io/vc.html},
year = {2021},
organization = "The University of Queensland, Australia. School of Languages and Cultures},
address = {Brisbane},
edition = {2021.09.29}
}sessionInfo()## R version 4.1.1 (2021-08-10)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 19043)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=German_Germany.1252 LC_CTYPE=German_Germany.1252
## [3] LC_MONETARY=German_Germany.1252 LC_NUMERIC=C
## [5] LC_TIME=German_Germany.1252
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] flextable_0.6.8 vowels_1.2-2 forcats_0.5.1 stringr_1.4.0
## [5] dplyr_1.0.7 purrr_0.3.4 readr_2.0.1 tidyr_1.1.3
## [9] tibble_3.1.4 ggplot2_3.3.5 tidyverse_1.3.1
##
## loaded via a namespace (and not attached):
## [1] Rcpp_1.0.7 lubridate_1.7.10 assertthat_0.2.1 digest_0.6.27
## [5] utf8_1.2.2 R6_2.5.1 cellranger_1.1.0 backports_1.2.1
## [9] reprex_2.0.1.9000 evaluate_0.14 httr_1.4.2 highr_0.9
## [13] pillar_1.6.2 gdtools_0.2.3 rlang_0.4.11 uuid_0.1-4
## [17] readxl_1.3.1 rstudioapi_0.13 data.table_1.14.0 klippy_0.0.0.9500
## [21] rmarkdown_2.5 labeling_0.4.2 munsell_0.5.0 broom_0.7.9
## [25] compiler_4.1.1 modelr_0.1.8 xfun_0.26 pkgconfig_2.0.3
## [29] systemfonts_1.0.2 base64enc_0.1-3 htmltools_0.5.2 tidyselect_1.1.1
## [33] fansi_0.5.0 crayon_1.4.1 tzdb_0.1.2 dbplyr_2.1.1
## [37] withr_2.4.2 MASS_7.3-54 grid_4.1.1 jsonlite_1.7.2
## [41] gtable_0.3.0 lifecycle_1.0.0 DBI_1.1.1 magrittr_2.0.1
## [45] scales_1.1.1 zip_2.2.0 cli_3.0.1 stringi_1.7.4
## [49] farver_2.1.0 fs_1.5.0 xml2_1.3.2 ellipsis_0.3.2
## [53] generics_0.1.0 vctrs_0.3.8 tools_4.1.1 glue_1.4.2
## [57] officer_0.4.0 hms_1.1.0 fastmap_1.1.0 yaml_2.2.1
## [61] colorspace_2.0-2 rvest_1.0.1 knitr_1.34 haven_2.4.3References
Hawkins, Sarah, and Jonathan Midgley. 2005. “Formant Frequencies of Rp Monophthongs in Four Age Groups of Speakers.” Journal of the International Phonetic Association 35 (2): 183–99.
Johnson, Keith. 2003. Acoustic and Auditory Phonetics. Malden, MA: Blackwell.
Ladefoged, Peter. 1996. Elements of Acoustic Phonetics. Chigago: University of Chicago Press.
Paganus, Annu, Vesa-Petteri Mikkonen, Tomi Mäntylä, Sami Nuuttila, Jouni Isoaho, Olli Aaltonen, and Tapio Salakoski. 2006. “The Vowel Game: Continuous Real-Time Visualization for Pronunciation Learning with Vowel Charts.” In International Conference on Natural Language Processing (in Finland), 696–703. Springer.
Rogers, Henry. 2014. The Sounds of Language: An Introduction to Phonetics. Routledge.
Styler, Will. 2013. “Using Praat for Linguistic Research.” University of Colorado at Boulder Phonetics Lab.
Zsiga, Elizabeth C. 2012. The Sounds of Language: An Introduction to Phonetics and Phonology. John Wiley & Sons.